Przegląd kodu źródłowego z modelu Fergusona – Sue Denim (pseudonim)
6 maj 2020
Źródło: Code Review of Ferguson’s Model
Imperial College London w końcu udostępnił pochodną kodu źródłowego z modelu Fergusona. Pomyślałem, że dokonam jego przeglądu i opiszę Wam niektóre spostrzeżenia. Nie znam waszego wykształcenia, więc przepraszam, jeśli niektóre z nich są na niewłaściwym poziomie poznania/zrozumienia.
Moje doświadczenie
Zajmowałem się pisaniem oprogramowania przez 30 lat. Pracowałem w Google w latach 2006-2014, gdzie byłem starszym inżynierem zajmującym się mapami, pocztą Gmail i bezpieczeństwem kont. Ostatnie pięć lat spędziłem w amerykańsko-brytyjskiej firmie, gdzie zaprojektowałem bazę danych firmy, pomiędzy innymi zadaniami i projektami. Przez kilka lat byłem także niezależnym konsultantem. Oczywiście wyrażam tylko własną profesjonalną opinię i nie mówię w imieniu mojego obecnego pracodawcy.
Przegląd kodu źródłowego z modelu Fergusona
Kod źródłowy
To nie jest kod, którego Ferguson użył, aby opracować swój słynny Raport nr 9. To, co zostało wydane na GitHub, jest mocno zmodyfikowaną pochodną, po ponad miesiącu aktualizacji przez zespół Microsoft i innych. Ten poprawiony kod źródłowy jest podzielony na wiele plików w celu zapewnienia czytelności i napisany w C ++, podczas gdy oryginalny program był „pojedynczym plikiem, posiadającym 15 000 linii, nad którym pracowano przez dekadę” (jest to uważane za wyjątkowo kiepską praktykę). Prośba o oryginalny kod została złożona 8 dni temu, ale zignorowano ją i prawdopodobnie będzie wymagany pewnego rodzaju przymus prawny, aby została spełniona. Najwyraźniej Imperial College jest zbyt zawstydzony tym stanem, by kiedykolwiek wydać kod z własnej woli. Jest to to nie do przyjęcia, biorąc pod uwagę, że zapłacili za to podatnicy, więc kod należy do nich.
Model
To, co tworzy model, najlepiej opisać jako „SimCity bez grafiki”. Model próbuje symulować gospodarstwa domowe, szkoły, biura, ludzi i ich ruchy itp. Nie będę zagłębiał się dalej w leżące u podstaw założenia, ponieważ jest to dobrze opisane w innych miejscach.
Wyniki niedeterministyczne
Z powodu błędów, kod może dawać bardzo różne wyniki, przy identycznych danych wejściowych.
Twórcy jednak rutynowo zachowują się tak, jakby to nie było ważne. Ten problem sprawia, że kod nie nadaje się do celów naukowych, biorąc pod uwagę, że kluczową częścią metody naukowej jest zdolność do powielania wyników. Bez powtarzalności odkrycia mogą być oderwane od rzeczywistości – o czym przekonano się na polu psychologii. Nawet jeśli ich oryginalny kod zostałby udostępniony, mam powody przypuszczać, że wyniki nie byłyby identyczne z tymi które opublikowano w raporcie 9. Wyniki nie-deterministyczne mogą wymagać pewnego wyjaśnienia, ponieważ nie jest to coś, co ktokolwiek wcześniej brał pod uwagę. W dokumentacji jest napisane:
„Model jest stochastyczny. Aby zobaczyć średnie zachowanie, należy wykonać wiele serii z różnymi ziarnami.”
„Stochastyczny” to tylko naukowo brzmiące słowo na „losowy”. Nie stanowi to problemu, jeśli przypadkowość jest zamierzoną pseudolosowością, tzn. przypadkowość pochodzi od początkowego „nasiona”, które jest iterowane w celu wytworzenia liczb losowych. Taka przypadkowość jest często stosowana w technikach Monte Carlo. Jest ona bezpieczna, ponieważ nasiona mogą być rejestrowane i te same (pseudo-)losowe liczby będą z nich wytwarzane w przyszłości. Każdy dzieciak, który grał w Minecraft jest zaznajomiony z pseudolosowością, ponieważ Minecraft obsługuje nasiona, których używa do generowania losowych światów, więc dzieląc się nasionami możesz dzielić się światami. Ewidentnie, w dokumentacji chcą, abyśmy myśleli, że biorąc pod uwagę materiał wyjściowy, model zawsze będzie dawał te same wyniki. Jednak analiza kodu ujawnia prawdę: model zwraca zasadniczo różne wyniki, nawet dla identycznych początkowych nasion i parametrów.
Zilustruję to kilkoma błędami. W zgłoszeniu o numerze 116 brytyjska „czerwona ekipa” z Uniwersytetu w Edynburgu donosi, że próbowała użyć trybu, w którym tabele danych przechowuje się w bardziej wydajnym formacie w celu szybszego ładowania i odkryła – ku swojemu zaskoczeniu – że wynikające z tego prognozy różniły się o około 80.000 zgonów po 80 dniach:
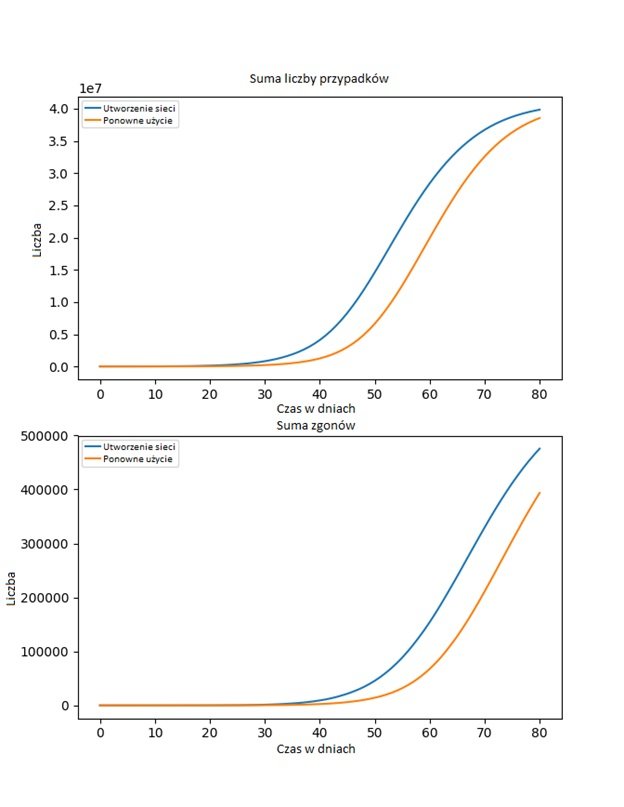
Ten tryb nie zmienia niczego w świecie, który jest symulowany, więc to był oczywiście błąd.
Odpowiedź zespołu z Imperial College jest taka, że to nie ma znaczenia: bo „są świadomi pewnych małych niedeterminizmów”, ale „historycznie uważano to za dopuszczalne ze względu na ogólną stochastyczną naturę modelu”. Zwróć uwagę na następujące sformułowanie: Imperial College wie, że ich kod zawiera takie błędy, ale działa tak, jakby była to jakaś nieodłączna losowość wszechświata, a nie wynik amatorskiego kodowania. Najwyraźniej w epidemiologii różnica 80 000 zgonów to „mały niedeterminizm”.
Imperial College doradził Edynburgowi, że problem zniknie, jeśli uruchomisz model w trybie jednordzeniowym, tak jak oni. Oznacza to, że sugerują używanie tylko jednego rdzenia procesora, a nie wielu rdzeni, które każda gra wideo z powodzeniem by wykorzystała. Dla symulacji kraju, użycie tylko jednego rdzenia CPU jest oczywiście poważnym problemem – tak dalekim od obliczeń na superkomputerach, jak to tylko możliwe. Niemniej jednak, właśnie w ten sposób Imperial College wykorzystuje kod: wie, że się rozkracza, gdy próbuje uruchomić go szybciej. Z lektury kodu jasno wynika, że w 2014 roku Imperial College próbował sprawić, aby kod wykorzystywał wiele procesorów do przyspieszenia go, ale nigdy nie sprawił, żeby działał niezawodnie. Wiadomo, że ten rodzaj programowania jest trudny i zazwyczaj wymaga starszych, doświadczonych inżynierów, aby uzyskać dobre wyniki. Wyniki, które losowo zmieniają się z uruchomienia na uruchomienie, są powszechną konsekwencją błędów bezpieczeństwa wątków. Bardziej potocznie, są one znane jako „Heisenbugs”.
Ale Edynburg wrócił i zgłosił, że – nawet w trybie jednordzeniowym – nadal widzi problem. Więc zrozumienie problemu przez Imperial College jest błędne. W końcu Imperial przyznaje, że istnieje błąd, powołując się na zmianę kodu, której dokonali, a która go naprawia. Podane wyjaśnienie brzmi: „Wygląda na to, że historycznie druga para nasion została użyta w tym momencie, aby uczynić przebiegi identycznymi, niezależnie od tego, jak została wykonana sieć, ale zostało to zmienione podczas implementacji resetowania nasion.” Innymi słowy, w procesie zmiany modelu uczynili go niedeterministycznym [nie replikowalnym] i nigdy tego zauważyli.
Dlaczego oni tego nie zauważyli? Ponieważ ich kod jest tak głęboko pogrążony w podobnych błędach i tak bardzo starali się je naprawiać, że wpadli w nawyk uśredniania wyników wielokrotnych przebiegów, aby to wszystko zatuszować… i ostatecznie to zachowanie zostało znormalizowane w zespole.
W zgłoszeniu o numerze 30 ktoś informuje, że model produkuje różne wyjścia w zależności od tego, na jakim komputerze jest uruchomiony (niezależnie od liczby procesorów). Ponownie, wyjaśnienie jest takie, że chociaż ten nowy problem „będzie kolejnym dodanym do listy innych” … „Nie stanowi to problemu gdy model jest uruchomiony jako całość, ponieważ i tak jest on stochastyczny.”
Chociaż naukowcem w tych wątkach nie jest Neil Ferguson, jest on w pełni świadomy, że kod jest wypełniony błędami, które tworzą losowe wyniki. W zmianie o numerze #107 jest autorem komentarza: „Zawiera poprawki do InitModel, aby zapewnić deterministyczne przebiegi z włączonymi wakacjami.” W zmianie numer #158 opisuje on zmianę tylko jako „Wiele małych zmian, niektóre krytyczne dla determinizmu.”
Imperial College próbuje mieć „ciastko i zjeść ciastko”. Zgłoszenia z przypadkowymi wynikami są odrzucane z odpowiedziami typu „to nie jest problem, po prostu uruchom algorytm wiele razy i weź średnią”, ale w tym samym czasie, twórcy naprawiają podobne błędy, kiedy sami je znajdują. Wiedzą, że ich kod nie wytrzyma kontroli, więc ukrywali to, dopóki profesjonaliści nie mieli szansy tego naprawić, ale szkody powstałe z ponad dekady amatorskiego hobbystycznego programowania są tak duże, że nawet Microsoft nie był w stanie sprawić, by model działał poprawnie.
Brak testów regresyjnych
W dyskusji nad poprawką do pierwszego błędu, Imperial College stwierdza, że kod był kiedyś deterministyczny w tym miejscu, ale zepsuli go przy zmianie kodu nie zauważając tego. Takie regresje są powszechne podczas pracy nad złożonym oprogramowaniem, dlatego też profesjonalne zespoły inżynierii oprogramowania piszą automatyczne testy regresyjne. Są to programy, które uruchamiają aplikację z różnymi wejściami, a następnie sprawdzają, czy wyniki są tym, czego się oczekuje. Po każdej proponowanej zmianie, testy są uruchamiane i jeśli jakikolwiek test zawiedzie, zmiana nie może zostać dodana. Kod napisany przez Imperial College nie ma prawdopodobnie działających testów regresyjnych. Próbowali, ale rozmiar losowych zachowań ich kodu, ich przerósł i polegli. 4 kwietnia powiedzieli:
„Nie mieliśmy czasu na wypracowanie skalowalnego i łatwego do utrzymania sposobu przeprowadzania testów regresysyjnych w sposób, który pozwoliłby na niewielką zmienność, i zarazem nie pozwoliłby na to, aby liczby rozjeżdżały się z czasem.”
Poza pozornie niemożliwą do uratowania naturą tego konkretnego kodu źródłowego, testowanie modelu przewidującego napotyka podstawowy problem. Autorzy nie wiedzą, jaka jest „poprawna” odpowiedź nawet długo po fakcie, a w międzyczasie kod i tak się zmienia ponownie, zmieniając w nim obecny zestaw błędów. Więc jest niejasne, co naprawdę oznaczają testy regresyjne dla takich modeli – nawet jeśli te modele miały kiedyś takie testy, które działały.
Nieudokumentowane równania
Duża część kodu składa się z formuł, dla których nie podano celu. John Carmack (legendarny programista gier wideo) przypuszczał, że część kodu mogła zostać automatycznie przetłumaczona z FORTRAN kilka lat temu. Na przykład, w linii 510 klasy SetupModel.cpp znajduje się pętla iterująca po wszystkich „miejscach”, o których wie symulacja. Wydaje się, że ten kod próbuje obliczyć R0 dla „miejsc”. Hotele są wykluczone podczas tego przejścia, bez wyjaśnienia.
Ten fragment kodu podkreśla problem, który Caswell Bligh omówił w komentarzach na swojej stronie: R0 nie jest prawdziwą cechą wirusa. R0 jest zarówno wejściem, jak i wyjściem tych modeli, i jest rutynowo dostosowywany do różnych środowisk i sytuacji. Modele, które konsumują swoje własne wyjścia jako wejścia, to problem dobrze znany sektorowi prywatnemu – może on prowadzić do szybkiej rozbieżności i błędnego przewidywania. Omówienie tego problemu znajduje się w sekcji 2.2 dokumentu Google „Uczenie się maszyn: wysoko oprocentowana karta kredytowa długu technicznego (Machine learning: the high interest credit card of technical debt)”.
Ciągły rozwój kodu źródłowego
Pomimo świadomości poważnych problemów w ich kodzie, na których naprawę „nie było czasu”, zespół z Imperial College kontynuuje dodawanie nowych funkcji; na przykład, model próbuje symulować wpływ aplikacji cyfrowego śledzenia kontaktów.
Dodawanie nowych funkcji do kodu źródłowego z tak wieloma problemami z jakością tylko je spotęguje i pogorszy. Jeśli zobaczyłbym takie coś w firmie, dla której świadczę usługę, natychmiast radziłbym zespołowi, aby zaprzestali opracowywania nowych funkcji, dopóki nie zostaną wprowadzone dokładne testy regresyjne i poprawiona jakość kodu.
Wnioski
Wszystkie prace oparte na tym kodzie powinny być natychmiast wycofane [retracted]. Wysiłki Imperial College w zakresie modelowania powinny zostać zresetowane. A prace rozpoczęte od zera z nowym zespołem, który nie podlega profesorowi Fergusonowi i który jest zobowiązany do powtarzalnych wyników z opublikowanym kodem od pierwszego dnia.
Na poziomie osobistym, posunąłbym się dalej i zasugerował, aby cała akademicka epidemiologia utraciła dotacje. Taką pracę najlepiej wykonuje sektor ubezpieczeniowy. Ubezpieczyciele zatrudniają ludzi od tworzenia modeli i naukowców zajmujących się danymi, ale zatrudniają również menedżerów, których zadaniem jest podjęcie decyzji, czy model jest wystarczająco dokładny dla rzeczywistego wykorzystania, a także profesjonalnych inżynierów oprogramowania, którzy zapewniają, że oprogramowanie modelowe jest odpowiednio przetestowane, zrozumiałe i tak dalej. Wysiłki środowiska akademickiego nie są wsparte takimi ludźmi, a wyniki mówią same za siebie.
Moja tożsamość
Sue Denim nie jest prawdziwą osobą. Postanowiłem pozostać anonimowy częściowo z powodu intensywnych przepychanek, związanych z zamknięciem krajów [lockdown], ale jest też głębszy powód. Ta sytuacja wydarzyła się z powodu szalejącego nadmiernego zaufania do dyplomów i stopni. Ja jestem już tym zmęczony. Jak pokazuje powszechnie konsternacja programistów, gdyby ktokolwiek w SAGE lub w rządzie pokazał kod pracującemu inżynierowi oprogramowania, wtedy wiedzieliby i natychmiast zaczęliby bić na alarm. Zamiast tego, rząd jest zdominowany przez naukowców, którzy najwyraźniej czują się niezdolni do kwestionowania czegokolwiek, co zrobił inny profesor. Tymczasem zwykłym obywatelom, takim jak ja, mówi się, że nigdy nie powinniśmy kwestionować „ekspertyzy”. Chociaż udowodniłem Toby’emu, że pracowałem w Google, to taka mentalność jest szkodliwa i musi się skończyć: proszę, oceń wnioski, które przygotowałem dla ciebie, lub poproś znanego ci i zaufanego programistę, aby ocenił je dla ciebie.
[Uwaga: analiza uzupełniająca jest teraz dostępna tutaj.]
Zobacz na: Epidemiolog Neil Ferguson drastycznie obniża prognozę śmiertelności z powodu COVID-19
Dane CDC sugerują że COVID-19 był w USA już w listopadzie 2019 roku
Jak rozumieć – i raportować – dane liczbowe dotyczące „zgonów Covid-19” – dr John Lee
Komentarze pod tekstem:
„Problemem jest natura rządu i polityki. Polityka to systematyczny sposób przenoszenia konsekwencji nieodpowiedniego lub nawet lekkomyślnego podejmowania decyzji na innych bez zgody, a często nawet wiedzy tych innych. Polityka i nauka są z natury przeciwstawne.
Nauka polega na odkrywaniu prawdy, bez względu na to, jak niewygodne lub niepożądane mogą być wyniki dla określonych zainteresowanych stron. Polityka polega na osiągnięciu celu zainteresowanych stron i ukryciu każdej prawdy, która mogłaby przeszkodzić temu celowi…”
„Problemem nie jest wirusologia, immunologia, a nawet zachowanie jakiejkolwiek choroby, która jest badana/symulowana. W artykule poruszana jest dyscyplina programistyczna zastosowana do modelowania. Wątpię, czy autor ma specjalistyczną wiedzę w danej dziedzinie, aby skomentować założenia immunologiczne (itp.) wbudowane w program. Autor ma specjalistyczną wiedzę programistyczną, aby stwierdzić, że model nie może wytworzyć użytecznego wyniku, bez względu na to, jak dokładne są założenia wirusologii/immunologii. Oprogramowanie, które przełożyło te założenia na prognozy / przewidywania infekcji i innych zgonów było tak źle napisane.”
Dzienna liczba potwierdzonych przypadków COVID-19 na milion, 3-dniowa średnia krocząca. USA, GB, Szwecja, Niemcy, Francja, Szwajcaria, Austria i Norwegia.
Dodatacje Gatesów i Imperial College
„Imperial College London ogłosiło dzisiaj, że Fundacja Billa i Melindy Gates przyznała dotację w wysokości 30 milionów dolarów (20 milionów funtów) na utworzenie inicjatywy kontroli schistosomatozy (Schistosomiasis Control Initiative – SCI).Parntnerstwo w Imperial College London obejmujące fundację, Światową Organizację Zdrowia i Harvard School of Public Health.” – 17 lipiec 2002, Grant of £20 million to establish the Schistosomiasis Control Initiative https://www.eurekalert.org/pub_releases/2002-07/icos-go071702.php
„Fundacja Billa i Melindy Gates ogłosiła przyznanie 8,6 miliona dolarów dotacji dla Imperial College w Londynie na opracowanie niedrogiego i szybkiego testu do pomiaru stanu zdrowia układu odpornościowego u pacjentów z HIV/AIDS w krajach rozwijających się.” – 26 listopad 2005, Gates Awards $8.6 Million to Imperial College London for HIV/AIDS Management Test https://philanthropynewsdigest.org/news/gates-awards-8.6-million-to-imperial-college-london-for-hiv-aids-management-test
„Ze swoim ostatnim wkładem w wysokości 35 milionów dolarów fundacja [Billa Gatesa] zainwestowała obecnie 75 milionów dolarów w projekt Target Malaria [Malaria na celowniku], który ma siedzibę w Imperial College w Londynie. Korzystając z technologii edycji genów CRISPR, zespołowi Target Malaria udało się zainstalować „napęd genowy” u przenoszącego malarię gatunku komara, który czyni samice gatunku bezpłodnymi.” – 8 września 2016, Gates Foundation Awards $35 Million for Mosquito Research https://philanthropynewsdigest.org/news/gates-foundation-awards-35-million-for-mosquito-research https://www.gatesfoundation.org/How-We-Work/Quick-Links/Grants-Database/Grants/2020/03/OPP1210755
„Dotacja w wysokości 14,5 miliona dolarów od Fundacji Billa i Melindy Gates pomoże grupie z Imperial College poprawić i rozszerzyć dostęp do opieki zdrowotnej w krajach rozwijających się.” – 12 grudzień 2018, $14.5m Gates Foundation grant to help improve global healthcare https://www.imperial.ac.uk/news/189502/145m-gates-foundation-grant-help-improve/